
What Is a Gene? How Is It Different from DNA?
- 演化之聲

- Mar 13
- 5 min read
Updated: Apr 10
To understand what a gene is, it is helpful to begin with chromosomes and gradually work inward through the levels of biological organization. Each species possesses a characteristic number of chromosomes. Humans, for example, have 23 pairs, peanuts have 20 pairs, coyotes have 39 pairs, and the plant Ophioglossum reticulatum contains an astonishing 630 pairs.
In eukaryotic cells, chromosomes reside within the nucleus. When a cell is not dividing, chromosomes do not appear as the familiar rod-shaped structures often illustrated in textbooks. Instead, they are dispersed throughout the nucleus in a threadlike form resembling tangled yarn, though they still maintain a particular spatial arrangement. As a cell prepares to divide, these threads condense into the compact rod-like chromosomes typically depicted in diagrams.
A chromosome is a structure composed of DNA tightly associated with many proteins, most prominently histones. Histones assemble into complexes called histone octamers, which form the core around which DNA is wrapped. Each histone octamer consists of histones H3, H4, H2A, and H2B (each of which also has several variants). Approximately 146 base pairs of DNA coil around a single histone octamer. The overall compactness of a chromosome depends on how tightly the DNA is wrapped around these proteins.


But what exactly is DNA? DNA stands for deoxyribonucleic acid. This molecule is a polymer composed of repeating units known as deoxyribonucleotides. These units are linked together by covalent bonds, meaning each deoxyribonucleotide functions as a building block of the DNA molecule. Every deoxyribonucleotide consists of three main components: a deoxyribose sugar, a nitrogenous base, and a phosphate group.
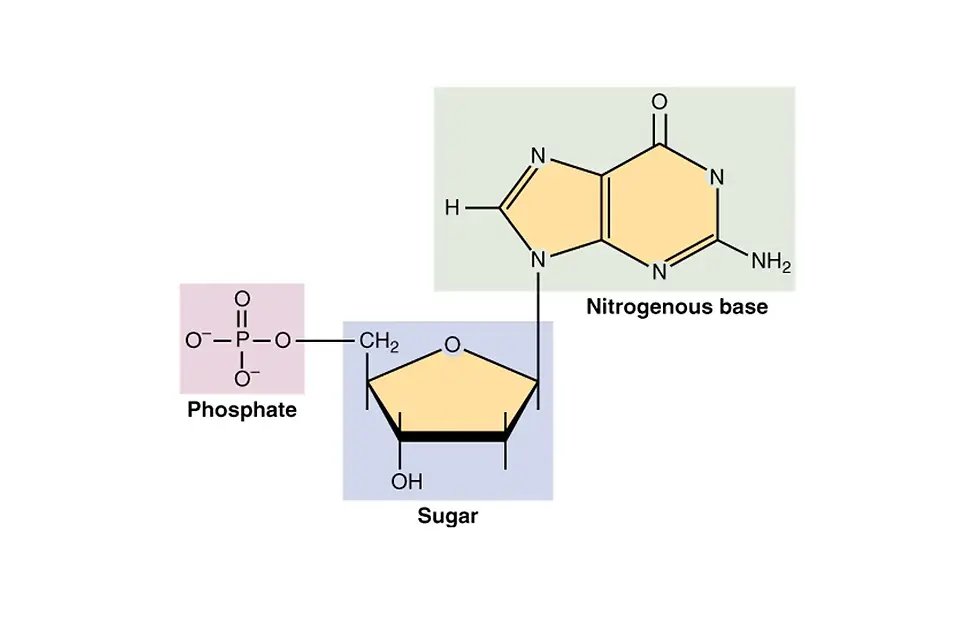
First, the sugar component is deoxyribose, a five-carbon sugar. The term “deoxy” indicates that the hydroxyl group (-OH) normally attached to the second carbon atom has lost its oxygen, leaving only a hydrogen atom attached to that carbon.

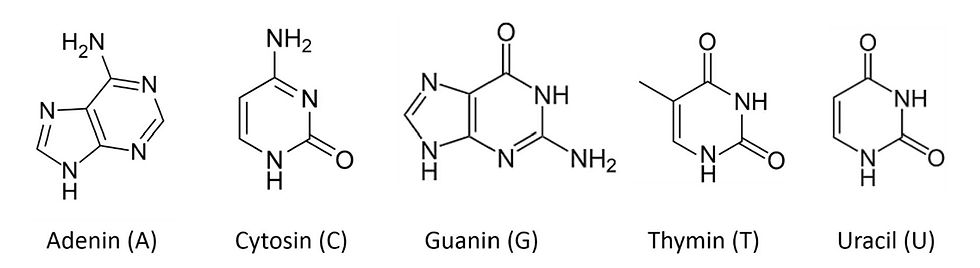
Second, DNA does not contain just one type of nucleotide. Instead, four different nucleotides exist, distinguished by the nitrogenous base attached to the sugar. These bases are adenine, guanine, cytosine, and thymine. They are commonly abbreviated by their initial letters: A, G, C, and T. These letters provide a convenient way to represent the composition of DNA, known as the DNA sequence.
The sequence can be arranged in countless combinations, and each gene possesses its own unique order of nucleotides. For instance, the first ten nucleotides of the β-actin gene are ATGGATGATG.
Third, the phosphate group attaches to the fifth carbon of the deoxyribose sugar and forms the linkage that connects one nucleotide to the next. Specifically, an oxygen atom from the phosphate group of one nucleotide bonds with the third carbon of the next nucleotide's sugar. Because of this arrangement, DNA has a directional structure. The chain runs from the fifth carbon of the first nucleotide to the third carbon of the final nucleotide. This orientation is described as the 5′ to 3′ direction, and all gene expression processes follow this direction.
Thus, the sequence mentioned earlier can be written as 5′-ATGGATGATG-3′.
DNA sequences arise from countless possible combinations of A, G, C, and T. Each gene contains its own distinctive DNA sequence, which is transcribed into RNA and often translated into a specific protein with a particular function.
In most living organisms, DNA exists as double-stranded DNA, meaning two DNA strands align in opposite directions and pair together to form a helical structure. Some viruses are exceptions, possessing single-stranded DNA as their genetic material, while others use single-stranded or double-stranded RNA (ribonucleic acid) instead.
The double helix of DNA usually forms a right-handed spiral, while left-handed forms are relatively rare. In some regions of the same DNA molecule, differences in base composition can lead to segments adopting slightly different helical conformations.
How do the two DNA strands pair with each other? The answer lies in the nitrogenous bases. Adenine pairs most stably with thymine through two hydrogen bonds, while cytosine pairs most stably with guanine through three hydrogen bonds. Each pairing is referred to as a base pair.

In the earlier example, the sequence contains ten base pairs. The entire DNA sequence of the β-actin gene, however, is about 1,125 base pairs long.

Each chromosome is composed of a single continuous DNA molecule, and these molecules can be extremely long. Human chromosome 1, for instance, contains roughly 249 million base pairs of DNA, while chromosome 2 contains about 242 million base pairs. Altogether, the 23 chromosomes in humans contain more than 3.2 billion base pairs.
Does this mean that the entire DNA sequence consists of genes? The answer is no.
A gene is defined as any region of DNA that can be transcribed into RNA. Some of these RNA molecules are translated into proteins; these RNA molecules are called messenger RNA (mRNA). Other RNAs do not encode proteins and are collectively known as non-coding RNAs. Examples include transfer RNA (tRNA), which carries amino acids during translation; ribosomal RNA (rRNA), which forms the core of ribosomes; small nuclear RNA (snRNA), involved in mRNA splicing; small nucleolar RNA (snoRNA), which modifies other RNAs; and long non-coding RNA (lncRNA), which participates in various regulatory processes.
What proportion of human DNA actually qualifies as genes? The approximate distribution is as follows:
DNA sequences that produce proteins: about 1.5%
DNA sequences that produce non-coding RNA: about 1.66%
Introns: about 26%
This means that less than 30% of the human genome may be considered part of genes. The remaining roughly 70% of DNA does not directly function as genes. In earlier decades, these regions were sometimes referred to as junk DNA because their functions were unknown. However, ongoing research has revealed that many of these sequences play important roles, such as regulating gene expression, maintaining chromosome stability, identifying regions required for chromosome separation during cell division, and influencing biological lifespan.
The roughly 70% of non-gene DNA includes many types of sequences:
SINEs (Short Interspersed Nuclear Elements): about 13.1%
LINEs (Long Interspersed Nuclear Elements): about 20.4%
LTR retrotransposons: about 8.3%
DNA transposons: about 2.9%
Simple repetitive sequences: about 3%
Pseudogenes and nonfunctional gene fragments: about 5%
Heterochromatin: about 8%
Specialized sequences: about 11.6%
Numerous studies have also shown that the abundance of repetitive sequences can influence processes such as cancer development and disease susceptibility.
The detailed functions of these sequences can be discussed another time.
Within chromosomes, genes are scattered much like islands across a vast ocean. For example, the β-actin gene in humans lies on chromosome 7 between base pairs 5,530,601 and 5,527,148 (values may vary slightly between individuals). The previous gene, FBXL18, is located about 13,339 base pairs away, while the next gene, FSCN1, is separated by about 62,215 base pairs. These genes are not closely adjacent.
In other words, genes occupy discrete segments along chromosomes. A gene is made of DNA, yet not all DNA qualifies as a gene.

Author: Shui-Ye You



Comments